# 事件循环和多进程
# 事件循环介绍
# 什么是事件循环
主线程从“任务队列”中读取事件,这个过程是循环不断的,所以整个运行机制又称为 Event Loops(事件循环)。
# 事件循环的本质
本质:在浏览器或者 nodejs 环境中,运行时对 js 脚本的调度方式。
# 不同环境中的事件循环
- 浏览器中的事件循环
为了协调事件(event),用户交互(user interaction),脚本(script),渲染(rendering),网路(networking)等,用户代理(user agent)必须使用事件循环(event loops)。
事件:postMessage,MutationObserver 等
用户交互:click,onScroll 等
渲染:解析 dom,css 等
脚本:js 脚本运行
- nodejs 中事件循环
事件循环允许 Node.js 执行非阻塞 I/O 操作,尽管 JavaScript 是单线程的,通过尽可能操作卸载到系统内核。由于大多数现代内核是多线程的,因此它们可以处理在后台执行的多个操作,当其中一个操作完成时,内核会告诉 Node.js,以便可以将相应的回调添加到轮询队列中以最终执行。
# 浏览器事件循环
# 为什么 js 是单线程的
浏览器 js 的作用是操作 DOM,这决定了它只能是单线程,否则会 DOM 操作冲突。
分析如下:
js 运行在浏览器中,是单线程的,每个 window 一个 js 线程。
浏览器是事件驱动的(Event driven),浏览器中很多行为是 异步(Asynchronized) 的。例如:鼠标点击事件、窗口大小拖拉事件、定时器触发事件、XMLHttpRequest 完成回调等。当一个异步事件发生的时候,它就进入事件队列。浏览器有一个内部大消息循环,Event Loop(事件循环),会轮询大的事件队列并处理事件。
事件循环有一个简单的工作——监视调用堆栈和回调队列。如果调用堆栈是空的,它将从队列中取出第一个事件,并将其推到调用堆栈,该堆栈有效地运行它。
# 宏任务与微任务
# 为什么要分微任务和宏任务?
微任务是线程之间的切换,速度快。不用进行上下文切换,可以快速的一次性做完所有的微任务。
宏任务是进程之间的切换,速度慢,且每次执行需要切换上下文。因此一个 Eventloop 中只执行一个宏任务。
而区分微任务和宏任务的根本原因是为了插队。由于微任务执行快,一次性可以执行很多个,在当前宏任务执行后立刻清空微任务可以达到伪同步的效果,这对视图渲染效果起到至关重要的作用。
# 概念
宏任务:当前调用栈中执行的代码成为宏任务。(主代码块,定时器等等)。
微任务: 当前(此次事件循环中)宏任务执行完,在下一个宏任务开始之前需要执行的任务,可以理解为回调事件。(promise.then,proness.nextTick 等等)。
宏任务中的事件放在 callback queue 中,由事件触发线程维护;微任务的事件放在微任务队列中,由js 引擎线程维护。
# 运行机制
- 宏任务进入主线程,执行过程中会收集微任务加入微任务队列。
- 宏任务执行完成之后,立马执行微任务中的任务。微任务执行过程中再次收集宏任务,并加入宏任务队列中。
- 当前微任务队列中的任务执行完毕,检查渲染,GUI 线程接管渲染。
- 渲染完毕后,js 线程接管,开启下一次事件循环,执行下一次宏任务(事件队列中取)。
- 宏任务(macrotask): srcipt(整体代码),setTimeout,setInterval,setImmediate,I/O,UI rendering。
- 微任务(microtask): process.nextTick,Promise,MutationObserver。
# 高频笔试题
setTimeout(() => {
console.log('setTimeout')
}, 0)
Promise.resolve().then(() => {
console.log('Promise')
Promise.resolve().then(() => {
console.log('Promise2')
})
})
console.log('main')
每轮事件循环执行一个宏任务和所有的微任务。
setTimeout(() => {
Promise.resolve().then(() => {
console.log('Promise')
})
}, 0)
Promise.resolve().then(() => {
setTimeout(() => {
console.log('setTimeout')
}, 0)
})
console.log('main')
任务队列一定会保持先进先出的顺序执行。
# setTimeout 是怎样工作的
console.log('Hi')
setTimeout(function cb1() {
console.log('Cb')
}, 5000)
console.log('Bye')
- Hi 添加到调用堆栈(Call Stack)中 >> 被执行显示在控制台 >> 从调用堆栈中被删除
- setTimeout 添加到调用堆栈(Call Stack)中 >> 被执行,Web APIs 中的浏览器创建计时器 >> 从调用堆栈中被删除
- Bye 添加到调用堆栈(Call Stack)中 >> 被执行显示在控制台 >> 从调用堆栈中被删除
- 5s 后,计时器完成并将 cb1 回调推到回调队列 >> 事件循环从回调队列中获取 cb1,并将其推到调用堆栈
- cb 添加到调用堆栈(Call Stack)中 >> 被执行显示在控制台 >> 从调用堆栈中被删除
- cb1 从调用堆栈中被删除 结果:Hi Bye Cb
setTimeout(callback, 0); 作用是告诉 js 引擎,在 0ms 以后把 callback 放到主事件队列中,等待当前的代码执行完毕再执行。
注意:重点是改变了代码流程,把 callback 的执行放到了等待当前的代码执行完毕再执行。调用 setTimeout,并将 0 作为第二个参数只是推迟回调,直到调用堆栈为空。
# 任务队列
js 单线程:它在运行时同一时刻只能做一件事,但是浏览器给我们提供了 webapi,它们可以对应的创建一些线程,但是你不能直接访问,只能通过某种方式去调用。
耗时的操作会阻塞调用栈,所以异步回调解决了这个问题。
堆栈溢出:函数循环调用等。
任务队列、回调队列:一般的 webapi 在结束后(计时结束、请求得到响应等)会把回调函数送到任务队列中。
事件循环:就是查看栈和任务队列,如果栈空就把任务队列队头压入栈中。之后这个任务得到执行。
setTimeout:所谓的时间并不是多久之后执行,而是最快要多久执行。
重绘必须等到调用栈空才能进行。
微任务的执行会因为 js 堆栈的情况有所不同。
<button class="btn">点击</button> <script> const btn = document.querySelector('.btn') btn.addEventListener('click', () => { Promise.resolve().then(() => console.log('Microtask 1')) console.log('Listener 1') }) btn.addEventListener('click', () => { Promise.resolve().then(() => console.log('Microtask 2')) console.log('Listener 2') }) // btn.click() // 通过直接点击按钮输出:Listener 1 >> Microtask 1 >> Listener 2 >> Microtask 2 // 通过直接调用btn.click()输出:Listener 1 >> Listener 2 >> Microtask 1 >> Microtask 2 </script>
# Web Worker
Web Worker 的作用,就是为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行。在主线程运行的同时,Worker 线程在后台运行,两者互不干扰。等到 Worker 线程完成计算任务,再把结果返回给主线程。这样的好处是,一些计算密集型或高延迟的任务,被 Worker 线程负担了,主线程(通常负责 UI 交互)就会很流畅,不会被阻塞或拖慢。
Worker 线程一旦新建成功,就会始终运行,不会被主线程上的活动(比如用户点击按钮、提交表单)打断。这样有利于随时响应主线程的通信。但是,这也造成了 Worker 比较耗费资源,不应该过度使用,而且一旦使用完毕,就应该关闭。
- 新建
web-worker.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>web-worker</title>
</head>
<body>
<p>计数: <output id="result"></output></p>
<button onclick="startWorker()">开始工作</button>
<button onclick="stopWorker()">停止工作</button>
<script>
let w
function startWorker() {
if (typeof Worker !== 'undefined') {
if (w === undefined) {
w = new Worker('http://127.0.0.1:8081/web-worker.js')
}
w.onmessage = function (event) {
document.getElementById('result').innerHTML = event.data
}
} else {
document.getElementById('result').innerHTML = '抱歉,你的浏览器不支持 Web Workers...'
}
}
function stopWorker() {
w.terminate() // 终止 web worker,并释放浏览器/计算机资源
w = void 0
}
</script>
</body>
</html>
- 新建
web-worker.js
let i = 0
let timer
function timedCount() {
i = i + 1
// postMessage() 方法 - 它用于向 HTML 页面传回一段消息
self.postMessage(i)
if (i >= 20) {
clearTimeout(timer)
console.log('计算已完成')
return
}
timer = setTimeout('timedCount()', 500)
}
timedCount()
- 参考资料
Web Worker 使用教程 (opens new window)
# nodejs 事件循环
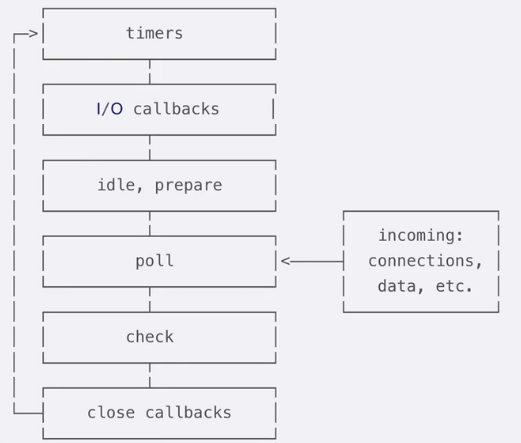
# 阶段概览
timers(定时器) : 此阶段执行那些由
setTimeout()和setInterval()调度的回调函数.I/O callbacks(I/O 回调) : 此阶段会执行几乎所有的回调函数, 除了 close callbacks(关闭回调) 和 那些由 timers 与
setImmediate()调度的回调.setImmediate 约等于 setTimeout(cb,0)
idle(空转), prepare : 此阶段只在内部使用
poll(轮询) : 检索新的 I/O 事件; 在恰当的时候 Node 会阻塞在这个阶段
check(检查) :
setImmediate()设置的回调会在此阶段被调用close callbacks(关闭事件的回调): 诸如
socket.on('close', ...)此类的回调在此阶段被调用
在事件循环的每次运行之间, Node.js 会检查它是否在等待异步 I/O 或定时器, 如果没有的话就会自动关闭.
# 代码执行场景
在 nodejs 中,setTimeout(fn, 0) === setTimeout(fn, 1)
在浏览器里,setTimeout(fn, 0) === setTimeout(fn, 4)
setTimeout(() => {
console.log('timeout')
}, 0)
setImmediate(() => {
console.log('immediate')
})
// setImmediate有时候是1ms之前执行,有时候又是1ms之后执行
以上代码执行顺序不确定,因为 event loop 的启动也是需要时间的,可能执行到 poll 阶段 已经超过了 1ms,此时 setTimeout 会先执行,反之 setImmediate 先执行
# process.nextTick
process.nextTick()不在 event loop 的任何阶段执行,而是在各个阶段切换的中间执行, 即从一个阶段切换到下一个阶段执行。
# EventEmitter
EventEmitter 有 2 个核心的方法,on 和 emit,node 自带订阅/发布模式
# nodejs 多进程
# 多进程和多线程介绍
进程是资源分配的最小单位,线程是 CPU 调度的最小单位
线程是进程的一个执行流,是 CPU 调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。一个进程由几个线程组成,线程与同属一个进程的其它的线程共享进程所拥有的全部资源。
一个进程下面的线程是可以去通信的,共享资源
进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程没有单独的地址空间,一个线程死掉就等于整个进程死掉。
谷歌浏览器
- 进程: 一个 tab 就是一个进程
- 线程: 一个 tab 又由多个线程组成,渲染线程,js 执行线程,垃圾回收,service worker 等等
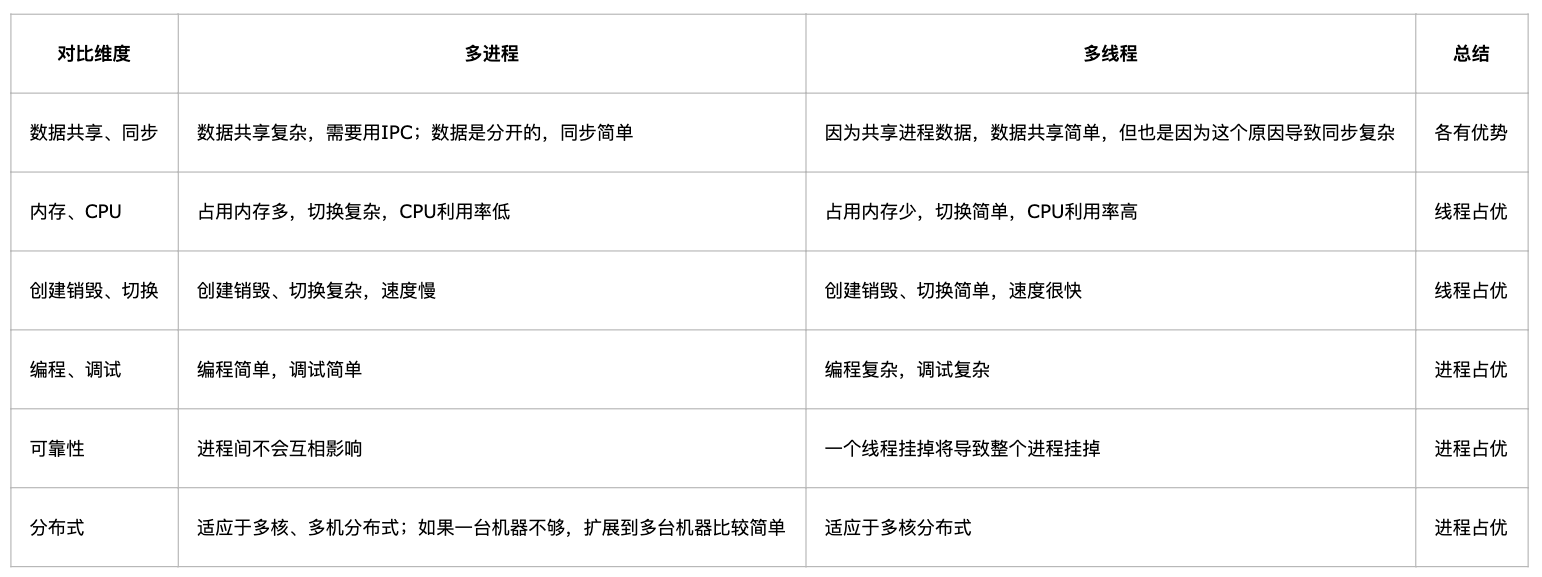
总结:线程快而进程可靠性高
# 创建多进程
利用 cluster 开启多进程
const cluster = require('cluster') // nodejs内置模块
const http = require('http')
const numCPUs = require('os').cpus().length
// cluster 基本原理,就是主进程fork子进程,然后管理它们。
if (cluster.isMaster) {
console.log(`主进程 ${process.pid} 正在运行`)
// 衍生工作进程
for (let i = 0; i < numCPUs; i++) {
cluster.fork()
}
cluster.on('exit', (worker, code, signal) => {
console.log(`工作进程 ${worker.process.pid} 已退出`)
})
} else {
http
.createServer((req, res) => {
res.end('hello world!')
})
.listen(3000, () => {
console.log('http://127.0.0.1:3000')
})
console.log(`工作进程 ${process.pid} 已启动`) // 执行8次,八核
}
# nodejs 调试方法
https://code.visualstudio.com/Docs/editor/debugging
vscode的 .vscode文件下面配置 launch.json
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "Launch Program",
"program": "${workspaceFolder}/chapter4/http_cluster.js"
}
]
}
# cluster 相关 API
Process 进程 、child_process 子进程 、Cluster 集群
# process 进程
process 对象是 Node 的一个全局对象,提供当前 Node 进程的信息,他可以在脚本的任意位置使用,不必通过 require 命令加载。
属性
- process.argv 属性,返回一个数组,包含了启动 node 进程时的命令行参数
- process.env 返回包含用户环境信息的对象,可以在 脚本中对这个对象进行增删改查的操作
- process.pid 返回当前进程的进程号
- process.platform 返回当前的操作系统
- process.version 返回当前 node 版本
方法
- process.cwd() 返回 node.js 进程当前工作目录
- process.chdir() 变更 node.js 进程的工作目录
- process.nextTick(fn) 将任务放到当前事件循环的尾部,添加到 ‘next tick’ 队列,一旦当前事件轮询队列的任务全部完成,在 next tick 队列中的所有 callback 会被依次调用
- process.exit() 退出当前进程,很多时候是不需要的
- process.kill(pid[,signal]) 给指定进程发送信号,包括但不限于结束进程
事件
beforeExit 事件,在 Node 清空了 EventLoop 之后,再没有任何待处理任务时触发,可以在这里再部署一些任务,使得 Node 进程不退出,显示的终止程序时(process.exit()),不会触发
exit 事件,当前进程退出时触发,回调函数中只允许同步操作,因为执行完回调后,进程金辉退出
uncaughtException 事件,当前进程抛出一个没有捕获的错误时触发,可以用它在进程结束前进行一些已分配资源的同步清理操作,尝试用它来恢复应用的正常运行的操作是不安全的
warning 事件,任何 Node.js 发出的进程警告,都会触发此事件
# child_process
nodejs 中用于创建子进程的模块,node 中大名鼎鼎的 cluster 是基于它来封装的。
- exec()
异步衍生出一个 shell,然后在 shell 中执行命令,且缓冲任何产生的输出,运行结束后调用回调函数
const exec = require('child_process').exec
const child = exec('ls')
child.stdout.on('data', function (data) {
console.log('stdout: ' + data)
})
child.stderr.on('data', function (data) {
console.log('stdout: ' + data)
})
child.on('close', function (code) {
console.log('closing code: ' + code)
})
上面的代码还有一个好处。监听 data 事件以后,可以实时输出结果,否则只有等到子进程结束,才会输出结果。所以,如果子进程运行时间较长,或者是持续运行,第二种写法更好。
- execSync()
exec()的同步版本
- execFile()
execFile 方法直接执行特定的程序 shell,参数作为数组传入,不会被 bash 解释,因此具有较高的安全性。
const { execFile } = require('child_process')
execFile('ls', ['-c'], (error, stdout, stderr) => {
if (error) {
console.error(`exec error: ${error}`)
return
}
console.log(`${stdout}`)
console.log(`${stderr}`)
})
- spawn()
spawn 方法创建一个子进程来执行特定命令 shell,用法与 execFile 方法类似,但是没有回调函数,只能通过监听事件,来获取运行结果。它属于异步执行,适用于子进程长时间运行的情况。
const { spawn } = require('child_process')
const child = spawn('ls', ['-c'], {
encoding: 'UTF-8'
})
child.stdout.on('data', function (data) {
console.log('data', data.toString('utf8'))
})
child.on('close', function (code) {
console.log('closing code: ' + code)
})
spawn 返回的结果是 Buffer 需要转换为 utf8
- fork()
fork 方法直接创建一个子进程,执行 Node 脚本,fork('./child.js') 相当于 spawn('node', ['./child.js']) 。与 spawn 方法不同的是,fork 会在父进程与子进程之间,建立一个通信管道 pipe,用于进程之间的通信,也是 IPC 通信的基础。
main.js
const child_process = require('child_process')
const path = require('path')
const child = child_process.fork(path.resolve(__dirname, './child.js'))
child.on('message', function (m) {
console.log('主线程收到消息', m)
})
child.send({ hello: 'world' })
child.js
process.on('message', function (m) {
console.log('子进程收到消息', m)
})
process.send({ foo: 'bar' })
# cluster
node 进行多进程的模块
属性和方法
- isMaster 属性,返回该进程是不是主进程
- isWorker 属性,返回该进程是不是工作进程
- fork() 方法,只能通过主进程调用,衍生出一个新的 worker 进程,返回一个 worker 对象。和 process.child 的区别,不用创建一个新的 child.js
- setupMaster([settings]) 方法,用于修改 fork() 默认行为,一旦调用,将会按照 cluster.settings 进行设置。
- settings 属性,用于配置,参数 exec: worker 文件路径;args: 传递给 worker 的参数;execArgv: 传递给 Node.js 可执行文件的参数列表
事件
- fork 事件,当新的工作进程被 fork 时触发,可以用来记录工作进程活动
- listening 事件,当一个工作进程调用 listen() 后触发,事件处理器两个参数 worker:工作进程对象
- message事件, 比较特殊需要去在单独的 worker 上监听。
- online 事件,复制好一个工作进程后,工作进程主动发送一条 online 消息给主进程,主进程收到消息后触发,回调参数 worker 对象
- disconnect 事件,主进程和工作进程之间 IPC 通道断开后触发
- exit 事件,有工作进程退出时触发,回调参数 worker 对象、code 退出码、signal 进程被 kill 时的信号
- setup 事件,cluster.setupMaster() 执行后触发
文档地址 (opens new window),英文版 (opens new window)
cluster 多进程模型
每个 worker 进程通过使用 child_process.fork()函数,基于 IPC(Inter-Process Communication,进程间通信),实现与 master 进程间通信。
# cluster 调度模型
cluster 是由 master 监听请求,再通过 round-robin 算法分发给各个 worker,避免了惊群 现象的发生。
round-robin:轮询调度算法的原理是每一次把来自用户的请求轮流分配给内部中的服务器。
# cluster 优雅退出和进程守护
# 优雅退出
- 关闭异常 Worker 进程所有的 TCP Server(将已有的连接快速断开,且不再接收新的连接),断开和 Master 的 IPC 通道,不再接受新的用户请求。
- Master 立刻 fork 一个新的 Worker 进程,保证在线的『工人』总数不变。
- 异常 Worker 等待一段时间,处理完已经接受的请求后退出。
if (cluster.isMaster) {
cluster.fork()
} else {
process.disconnect()
}
# 进程守护
master 进程除了负责接收新的连接,分发给各 worker 进程处理之外,还得像天使一样默默地守护着这些 worker 进程,保障整个应用的稳定性。一旦某个 worker 进程异常退出就 fork 一个新的子进程顶替上去。
cluster.on('exit', () => {
cluster.fork()
})
cluster.on('disconnect', () => {
cluster.fork()
})
# IPC 通信
IPC 通信就是进程间的通信。
虽然每个 Worker 进程是相对独立的,但是它们之间始终还是需要通讯的,叫进程间通讯(IPC)。下面是 Node.js 官方提供的一段示例代码
'use strict'
const cluster = require('cluster')
if (cluster.isMaster) {
const worker = cluster.fork()
worker.send('hi there')
worker.on('message', msg => {
console.log(`msg: ${msg} from worker#${worker.id}`)
})
} else if (cluster.isWorker) {
process.on('message', msg => {
process.send(msg)
})
}
细心的你可能已经发现 cluster 的 IPC 通道只存在于 Master 和 Worker 之间,Worker 与 Worker 进程互相间是没有的。那么 Worker 之间想通讯该怎么办呢?通过 Master 来转发。
核心: worker 直接的通信,靠 master 转发,利用 workder 的 pid。
← HTTP缓存 Rollup模块打包器 →